转载于推特用户shellac
如果你正在阅读本文,你可能已经意识到订阅 Claude 方案比使用 API 要划算得多。但具体划算多少,以及实际的限制究竟是什么?我通过两个未舍入的浮点数提取了精确数值,并发现了一些值得注意的现象。我稍后会解释具体的实现方法,首先展示结果。
研究发现
20× 方案的性价比并不如预期。在 Anthropic 的官网上,所有提及“20× 更多使用量*”的地方都带有那个烦人的星号,而这个星号承载了大量附加条件。虽然五小时的会话限制确实比 Pro 版高出 20 倍,但真正的核心问题在于,你每周能完成多少工作量?答案是:每周仅为 5× 方案的两倍。
另一方面,5× 方案提供了极佳的性价比。其实际表现显著超出了其承诺的价值,是价格表中最理想的选择。你获得的会话限制是 Pro 版的 6 倍(而非 5 倍),且每周限制是 Pro 版的 8 倍以上(超过了其名称所示的 5 倍)。

与 API 定价相比,所有方案的表现都极为出色。表中的价值估算为下限值,因为缓存机制使得实际的 API 等效价值更具优势(稍后我将对此进行详细解释)。无论如何,若能采用方案定价而非 API 定价,请务必选择前者。

表格中未包含但非常重要的一点
Warning
缓存读取。它们是完全免费的。
这使得计算结果更加倾向于订阅方案。在智能体循环(例如 Claude Code)中,模型每轮会进行数十次工具调用。每次工具调用后,模型都会被再次调用,并对整个上下文进行缓存读取。API 对每次读取收取 10% 的费用;而订阅方案则不收取任何费用。正如我们稍后所见,这种差异会迅速累积。
缓存写入同样享有折扣,在 API 中其成本为输入价格的 1.25 倍或 2 倍 1 ,而在订阅方案中则按常规输入价格计费。由于每一轮对话在读取前都必须写入缓存,因此这一点也至关重要。
额度 (credits)
那么,我一直提到的这些额度究竟是什么?
它们是内部用于追踪套餐使用情况的单位。“额度”(Credits)是我对其的任意命名,这些数值并不会直接出现在任何 API 字段中,因此没有明确的术语来定义它们。我认为“额度”一词表达尚可。
我们如何将额度转换为 Token 数量?公式如下
credits_used = ceil(input_tokens × input_rate + output_tokens × output_rate)
……以及你带入其中的数值:
| Model | Input credits/token | Output credits/token |
|---|---|---|
| Haiku | 2/15 = 0.133… | 10/15 = 2/3 = 0.666… |
| Sonnet | 6/15 = 2/5 = 0.4 | 30/15 = 2 |
| Opus | 10/15 = 2/3 = 0.666… | 50/15 = 10/3 = 3.333… |
这些具体数值看起来相当随意,但它们之间的比例反映了 API 的定价逻辑:输出成本是输入的 5 倍,Opus 的费用是 Haiku 的 5 倍,依此类推。
让我们用一些实际数据来进行测试。
我们首先从现实的最坏情况开始:虽然启用了缓存,但缓存处于冷启动状态。(真正的最坏情况是完全禁用缓存,但这较为罕见。)
冷缓存(100K 缓存写入 + 1K 输出)
Subscription credits
ceil(100K × 2/3 + 1K × 10/3) = 70,000
API cost
Cache write: 100K × $5/M × 1.25 = $0.625
Output: 1K × $25/M = $0.025
Total: $0.650
Max 5× weekly
floor(41,666,700 / 70,000) = 595 req/wk
595 × $0.650 = $386.75/week
$386.75 × 52/12 = $1,676/mo
You’re paying $100/mo → 16.8× value
这已经具备了极高的价值,并且是现实世界中的基准情况(即使在关闭缓存的情况下,它仍约为 13 倍)。一旦进入循环且缓存处于热启动状态,表现会更佳:
热缓存(100K 缓存读取 + 1K 缓存写入 + 1K 输出)
请注意,在订阅端我们仅计算 1K 个新标记(tokens)。而在 API 端,100K 的缓存读取仍需支付输入成本的 10%。
Subscription credits
ceil(1K × 2/3 + 1K × 10/3) = 4,000
API cost
Cache read: 100K × $5/M × 0.1 = $0.05
Cache write: 1K × $5/M × 1.25 = $0.00625
Output: 1K × $25/M = $0.025
Total: $0.08125
Max 5× weekly
floor(41,666,700 / 4,000) = 10,416 req/wk
10,416 × $0.08125 = $846.30/week
$846.30 × 52/12 = $3,667/mo
You're paying $100/mo -> **36.7× value**
其价值比 API 高出三十六倍以上。
取证分析
我是如何获得所有这些数字的?
去年秋天,Claude.ai 设置页面出现了一个新选项卡。该“使用情况”选项卡通过两个进度条显示您的剩余额度。很快,我就发现自己频繁地在 Claude 聊天界面与该页面之间切换。特别是在聊天内容较长的情况下(且未进行缓存,但这属于另一回事),这些额度可能会迅速耗尽。
我决定开发一个 插件 。 3 首先,我研究了使用情况页面(usage page)本身的实现方式。逻辑非常直接,一个 /usage 端点返回一个微小的 JSON 代码段,其中的数值被舍入到最接近的百分点。这对我来说已经足够了,因为我真正想要的是一种更简便的方式来查看这些数字。
但我继续深入挖掘,很快发现了一些有趣的现象。在一个 Max 5× 账户中,生成端点的 SSE 响应包含未经过舍入的 double 类型 usage 值: 0.16327272727272726 。
这些数值精确得令人生疑。看起来非常像是某种分数转换成的十进制小数。我们能否恢复底层的原始分数并获取真实的限制?事实证明是可以的。
第一步:区间化(bucket)
当一个实数转换为浮点数时,它会舍入到最接近的可表示值。该浮点数代表了所有会舍入到该值的微小区间 [L, U) 内的有理数。在我们处理的 0–1 范围内,该区间的宽度约为 10 −17 。
原始分数(在转换为浮点数之前)必须位于该 [L, U) 区间内。我们的目标是从该区间中提取出最简分数。
为什么要找最简分数?任何十进制小数都可以转换为普通分数,但这并不能提供更多信息(例如:16327272727272726/100000000000000000)。我们希望获取的是原始分数(其分母推测应小于 100 兆)。
但是,假设原始分数为 2/10,我们将恢复出 1/5!获取最简分数是否会导致误报?对于单一样本而言,确实如此。这就是为什么我们需要获取多个样本并在随后计算最小公倍数的原因。如果真实分母是 10,我们有时会恢复出 5 或 2(因为所有结果都会被约分),但绝不会恢复出一个不能整除 10 的分母。因此,最小公倍数只会增加,而不会超过真实限制值。经过多次采样后,真实分母高于此值的概率将变得微乎其微。
步骤 2:数学处理
回到这一区间(bucket)的问题,我们如何从中找到最简分数?
Stern-Brocot 树是对所有正分数进行的二分搜索,按数值排序,但在构建上确保先发现较简分数。从 0/1 和 1/0(无穷大)开始,每一步都向目标区间收缩。以下是寻找 0.4 对应分数的示例:
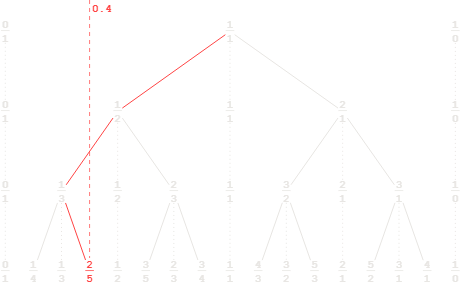
在我们的应用场景中,目标并非精确数值,而是一个极小的区间(约 10 −17 )。无论采用哪种方式,其处理过程在本质上是相同的。
回到我们最初的 0.16327272727272726 。桶内的第一个命中项是一个分母极小的分数(通常是具有最小分母的项):
step 00: left=0/1 right=∞ mediant=1 -> mediant ≥ U, move left
step 01: left=0/1 right=1/1 mediant=1/2 -> mediant ≥ U, move left
step 02: left=0/1 right=1/2 mediant=1/3 -> mediant ≥ U, move left
step 03: left=0/1 right=1/3 mediant=1/4 -> mediant ≥ U, move left
step 04: left=0/1 right=1/4 mediant=1/5 -> mediant ≥ U, move left
step 05: left=0/1 right=1/5 mediant=1/6 -> mediant ≥ U, move left
step 06: left=0/1 right=1/6 mediant=1/7 -> mediant < L, move right
step 07: left=1/7 right=1/6 mediant=2/13 -> mediant < L, move right
step 08: left=2/13 right=1/6 mediant=3/19 -> mediant < L, move right
... 57 more steps ...
step 66: left=8/49 right=417/2554 mediant=425/2603 -> mediant ≥ U, move left
step 67: left=8/49 right=425/2603 mediant=433/2652 -> mediant ≥ U, move left
step 68: left=8/49 right=433/2652 mediant=441/2701 -> mediant ≥ U, move left
step 69: left=8/49 right=441/2701 mediant=449/2750 -> HIT
往返检查: 449/2750 打印为 0.16327272727272726 ✓
步骤 3:最小公分母
每个样本都提供一个分母。真实的限制值 D 必须能被所有这些分母整除。例如: 449/2750 和 11401/75000 均可换算为分母 3,300,000 。
为什么限制值必须能被所有这些数整除?因为利用率数值的定义严格对应“已使用量 / 限制值”。当我们从浮点数中恢复分数时,得到的是约分后的结果。因此,我们恢复的分母只能是真实限制值的约数。
因此,你需要抽取一些样本,收集这些分母,并计算它们的最小公倍数(LCM)。起初,这个数值会剧烈波动,随后趋于稳定。一旦它在多种不同的使用量下保持不变,该最小公倍数即为你的限制值。尽管仍存在极小的概率出现偏差,但在多次采样后,这种可能性将变得微乎其微。
第 4 步:Feynman method
最后,我是如何获得额度-Token(credit-token)公式和模型乘数的?最初是进行大量的手动数据收集,随后在我修改了扩展程序以在聊天时自动保存这些数据后,转为自动化数据采集。我将所有数据汇总到表格中并反复观察。我咨询了 Claude,也咨询了 GPT。通过提出假设并进行测试,最终得出了上述表格和公式。我希望在此能有更多细节分享,但这确实是一个有些混乱的过程,且我没有做详细笔记。重点在于我已经验证了最终数据,它们完全吻合。
结论
侧信道无处不在。我认为 Anthropic 的任何人都没有预料到,仅仅因为忘记对两个数字进行取整,就会泄露其确切的价格表。
如果条件允许,你应该订阅套餐。相比于 API 计费,Claude Code 在 API 上的定价对大多数人来说在经济上并不划算。主要的例外情况是,如果你由于组织原因(企业/团队设置、采购等)被迫使用 API,在这种情况下,这种比较的相关性较低。
如果你关注 Claude 的使用限制(既然你已经读到了这篇详细解释限制的文章末尾,我假设你确实关注),请尝试我的 Claude Counter 扩展程序 。它能显示缓存计时器,并在编辑框中直接显示使用进度条(具有完整的精度)以及更多功能。
截至本文撰写时,这些浮点数仍未取整,且保持着疑点重重的精确度。我预计如果这篇文章引起关注,这种现状可能维持不了多久。我会感到有些遗憾,因为这会让我的扩展程序功能略微受损。(我将不得不依赖 /usage 端点,即官方使用情况页面所使用的那个经过取整处理的端点)