对于向深入学习上下文工程(Context Engineering)的同学,这又是一篇必看的文章。
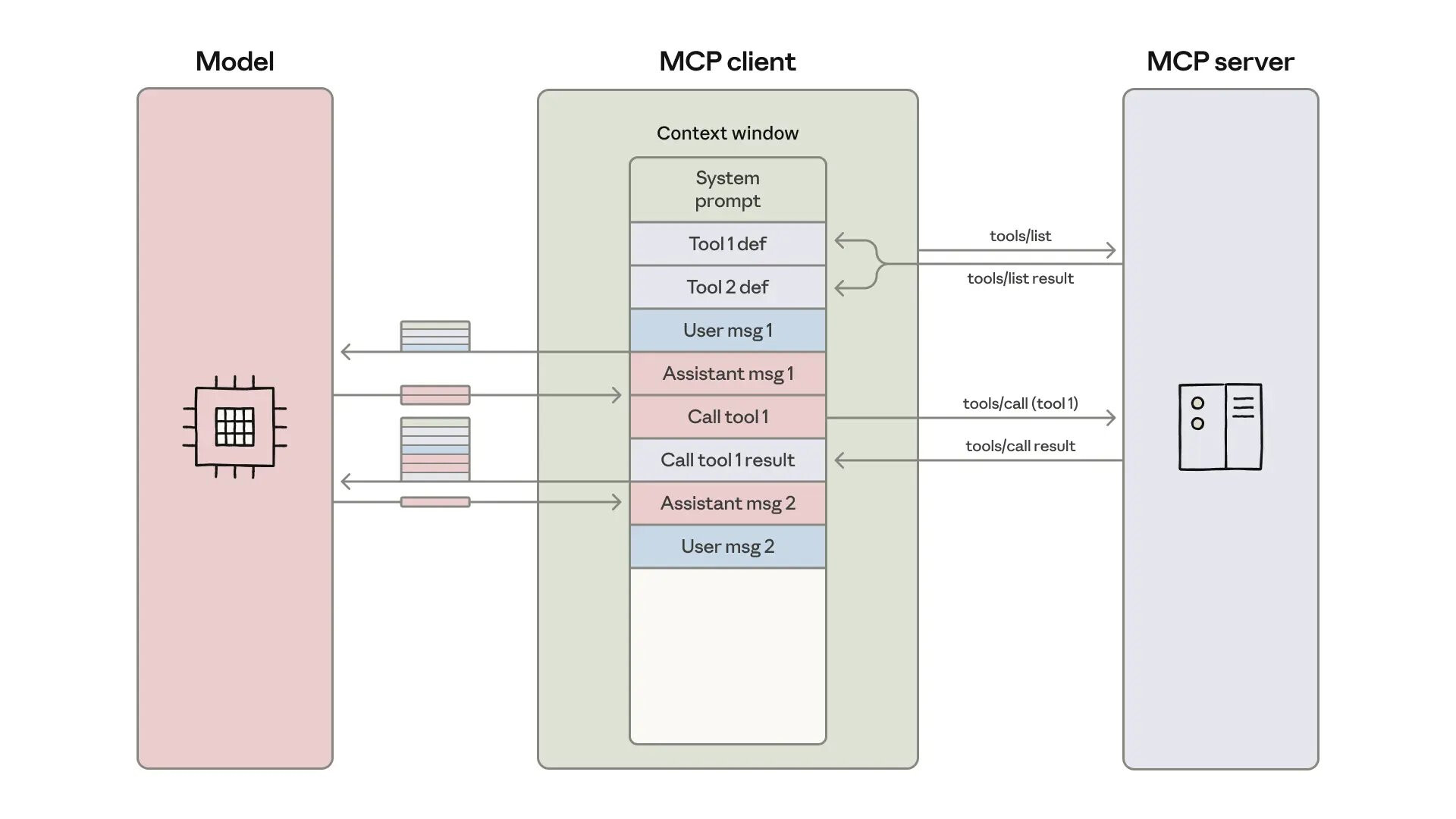
这篇文章讲的是如何解决 MCP 工具太多的问题,但凡你做过 Agent 开发,用了大量 MCP 工具,就会知道 MCP 工具多了后最大的问题就是上下文占用太多,不仅导致成本高,还会影响推理和生成质量。
另外一个问题就是 MCP 工具返回的中间结果也会挤占大量的上下文空间。
看这文章的时候忍不住夸了一下 Manus,他们确实在上下文工程方面探索的很深入了,里面的工程技巧和他们以前分享过的很类似(我一会把之前分享过的 Manus 相关的文章在评论也发一下)。
Anthropic 的方案也很简单直接,就是把“代码”也当作工具的一种,然后从代码中去调用 MCP。
这样做有很多好处:
- 解决了系统提示词中工具定义太多的问题
不需要在系统提示词中加载所有 MCP 工具,只需要定义一个“代码”工具。
那需要工具了怎么办呢?
这些代码都保存在统一的目录下,去目录检索下就能找到合适的工具了,比如这是文中的一个目录示例:
servers
├── google-drive
│ ├── getDocument.ts
│ ├── … (other tools)
│ └── index.ts
├── salesforce
│ ├── updateRecord.ts
│ ├── … (other tools)
│ └── index.ts
└── … (other servers)
找不到现成的工具怎么办?
直接现写一个!写完了还可以保存起来下次继续用。
- 解决了 MCP 工具返回结果太长的问题
比如说我们要用 MPC 工具获取 1 万行数据后筛选转换出合格的数据,就可以先从代码中调用 MCP 工具获取这 1 万行数据,然后从代码中去筛选过滤,最后只返回 5 条数据,这样上下文中就只需要保留那 5 条过滤的数据,而不是像以前一样有 1 万条数据在里面。
- 解决了数据隐私问题
如果你直接使用 MCP 工具,工具返回的数据都要加载到上下文每次上传给 LLM,用代码就可以对敏感数据先二次处理再加到上下文
- 中间结果持久化和技能沉淀
代码可以把一些中间结果写入文件保存到硬盘,一方面可以不占用上下文空间,另一方面也可以随时从硬盘避免反复调用 MCP。
还有就是虽然很多代码是临时生成的,但是这些临时生成的代码可以保存下来,沉淀为“技能”(Skill),加上 SKILL .MD 文件就和 Claude Code 的技能一样可以被反复使用了。