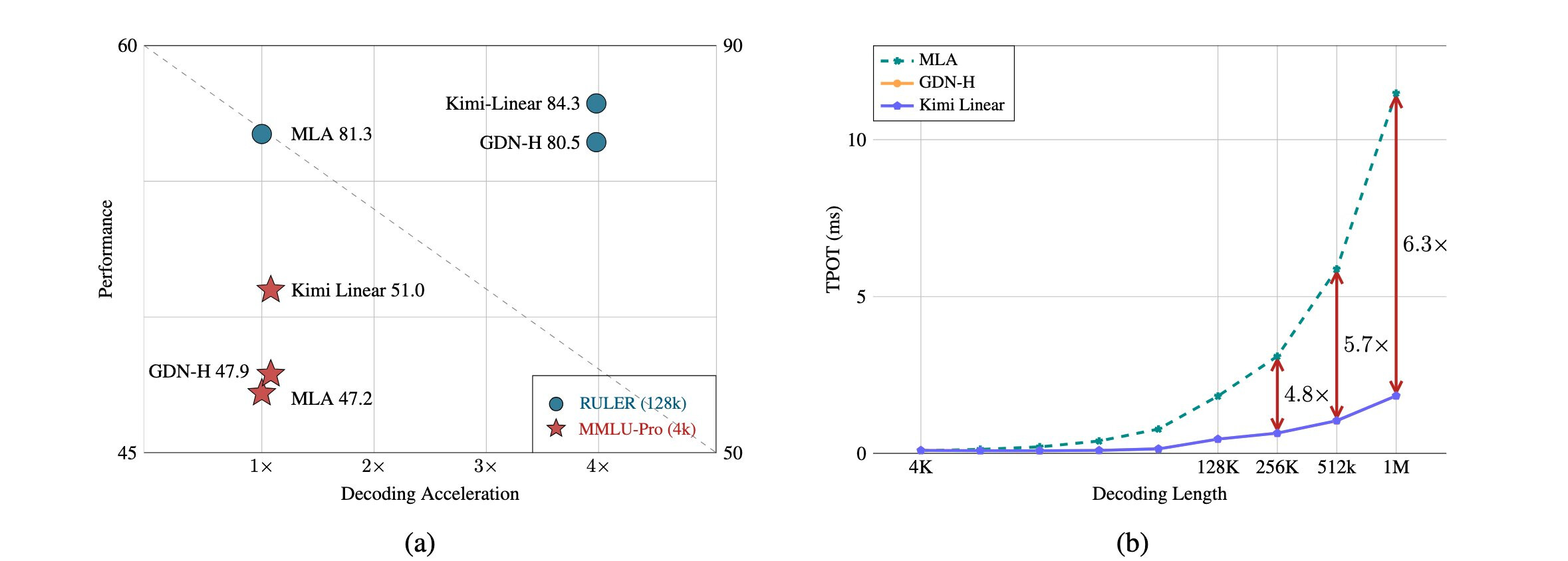
Kimi最近发力了,刚刚放出来一款:Kimi Linear,在1M 上下文长度下,KV缓存减少75%,解码吞吐提升6倍
MMLU-Pro(4k 上下文)得分 51.0,速度与全注意力相当
RULER(128k 上下文)得分 84.3,速度提升3.98倍
1M token超长序列,解码吞吐比MLA快6.3倍
Kimi Linear把Transformer里最耗内存最拖速度的全注意力,大部分换成了硬件友好的线性注意力,3层+1层混合比例,省显存,提高了长文本生成速度
对长上下文应用的场景,可以更便宜、快速落地了